
How are we doing? Lets enter the following magics into our first cell and run it: Lets run our first code cell (boilerplate code) to start an interactive notebook session within a few seconds: Next, read the NYC yellow taxi data from the S3 bucket into an AWS Glue dynamic frame: View a few rows of the dataset with the following code: Now, read the taxi zone lookup data from the S3 bucket into an AWS Glue dynamic frame: Based on the data dictionary, lets recalibrate the data types of attributes in dynamic frames corresponding to both dynamic frames: Get a record count with the following code: Next, load both the dynamic frames into our Amazon Redshift Serverless cluster: First, we count the number of records and select a few rows in both the target tables (. Below is the code to perform this: If your script creates a dynamic frame and reads data from a Data Catalog, you can specify the role as follows: In these examples, role name refers to the Amazon Redshift cluster role, while database-name and table-name relate to an Amazon Redshift table in your Data Catalog. For more information, see the AWS Glue documentation. You should see two tables registered under the demodb database. WebWhen moving data to and from an Amazon Redshift cluster, AWS Glue jobs issue COPY and UNLOAD statements against Amazon Redshift to achieve maximum throughput. Automate encryption enforcement in AWS Glue, Calculate value at risk (VaR) by using AWS services. An AWS Glue job is provisioned for you as part of the CloudFormation stack setup, but the extract, transform, and load (ETL) script has not been created. Below are the steps you can follow to move data from AWS Glue to Redshift: AWS Glue creates temporary credentials for you using the role you choose to run the job by default. If this is the first time youre using the Amazon Redshift Query Editor V2, accept the default setting by choosing. Amazon S3 Amazon Simple Storage Service (Amazon S3) is a highly scalable object storage service. By continuing to use the site, you agree to the use of cookies. Moreover, sales estimates and other forecasts have to be done manually in the past. (This architecture is appropriate because AWS Lambda, AWS Glue, and Amazon Athena are serverless.) Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. For instructions, see the Secrets Manager documentation. AWS Glue AWS Glue is a fully managed ETL service that makes it easier to prepare and load data for analytics. Understanding Select it and specify the Include path as database/schema/table. Jobs in AWS Glue can be run on a schedule, on-demand, or in response to an event. Unable to move the tables to respective schemas in redshift. Rename the temporary table to the target table. 2. To run the crawlers, complete the following steps: On the AWS Glue console, choose Crawlers in the navigation pane. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. Connecting to Amazon Redshift in Astera Centerprise Otherwise you would have to create a JSON-to-SQL mapping file. If this is the first time youre using the Amazon Redshift Query Editor V2, accept the default setting by choosing. How to convince the FAA to cancel family member's medical certificate? To learn more about Lambda UDF security and privileges, see Managing Lambda UDF security and privileges. Write data to Redshift from Amazon Glue. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. To run the crawlers, complete the following steps: When the crawlers are complete, navigate to the Tables page to verify your results. Method 3: Load JSON to Redshift using AWS Glue. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. He loves traveling, meeting customers, and helping them become successful in what they do. This is continuation of AWS series. JSON auto means that Redshift will determine the SQL column names from the JSON. Migrating Data from AWS Glue to Redshift allows you to handle loads of varying complexity as elastic resizing in Amazon Redshift allows for speedy scaling of computing and storage, and the concurrency scaling capability can efficiently accommodate unpredictable analytical demand. Create a new secret to store the Amazon Redshift sign-in credentials in Secrets Manager. Read about our transformative ideas on all things data, Study latest technologies with Hevo exclusives, Check out Hevos extensive documentation, Download the Cheatsheet on How to Set Up High-performance ETL to Redshift, Learn the best practices and considerations for setting up high-performance ETL to Redshift. CSV in this case. AWS Glue is an ETL (extract, transform, and load) service provided by AWS. Ayush Poddar  You can also access the external tables dened in Athena through the AWS Glue Data Catalog. and then paste the ARN into the cluster. You can also deduplicate your data using AWS Glue. Step 2: Specify the Role in the AWS Glue Script. Job bookmarks store the states for a job. You dont need to put the region unless your Glue instance is in a different. Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools. Post Syndicated from Aaron Chong original https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/. There are several ways to load data into Amazon Redshift. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number.
You can also access the external tables dened in Athena through the AWS Glue Data Catalog. and then paste the ARN into the cluster. You can also deduplicate your data using AWS Glue. Step 2: Specify the Role in the AWS Glue Script. Job bookmarks store the states for a job. You dont need to put the region unless your Glue instance is in a different. Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools. Post Syndicated from Aaron Chong original https://aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/. There are several ways to load data into Amazon Redshift. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number.  Follow Amazon Redshift best practices for table design. The default database is dev. We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping.
Follow Amazon Redshift best practices for table design. The default database is dev. We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping.  Validate your Crawler information and hit finish. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. The following diagram describes the solution architecture. Choose the link for the Redshift Serverless VPC security group.
Validate your Crawler information and hit finish. Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. The following diagram describes the solution architecture. Choose the link for the Redshift Serverless VPC security group.  Use EMR. Why won't this circuit work when the load resistor is connected to the source of the MOSFET? It uses Amazon EMR, Amazon Athena, and Amazon Redshift Spectrum to deliver a single view of your data through the Glue Data Catalog, which is available for ETL, Querying, and Reporting. Next, we will create a table in the public schema with the necessary columns as per the CSV data which we intend to upload. We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case.
Use EMR. Why won't this circuit work when the load resistor is connected to the source of the MOSFET? It uses Amazon EMR, Amazon Athena, and Amazon Redshift Spectrum to deliver a single view of your data through the Glue Data Catalog, which is available for ETL, Querying, and Reporting. Next, we will create a table in the public schema with the necessary columns as per the CSV data which we intend to upload. We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. 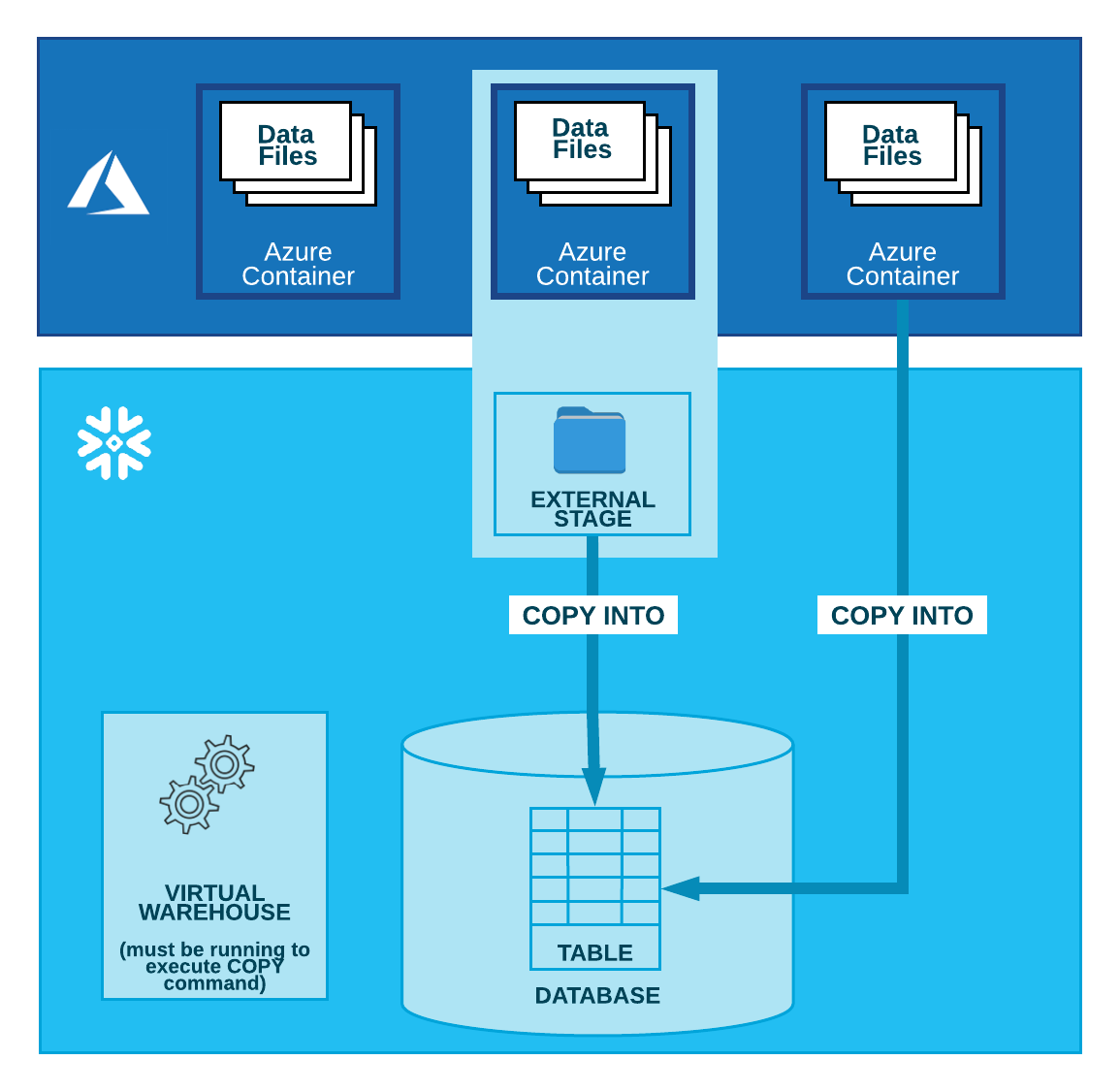 Add a self-referencing rule to allow AWS Glue components to communicate: Similarly, add the following outbound rules: On the AWS Glue Studio console, create a new job. You may access the instance from the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key AWSCloud9IDE. Launch the Amazon Redshift cluster with the appropriate parameter groups and maintenance and backup strategy. When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or protected health information (PHI), is a common requirement, especially for those in highly regulated industries with strict data security and privacy mandates. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue. What is the de facto standard while writing equation in a short email to professors? For more information, see Implementing workload management in the Amazon Redshift documentation. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. If you've got a moment, please tell us what we did right so we can do more of it. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. If not, this won't be very practical to do it in the for loop. Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools. Not the answer you're looking for? For more information, see the AWS Glue documentation. If you've got a moment, please tell us how we can make the documentation better.
Add a self-referencing rule to allow AWS Glue components to communicate: Similarly, add the following outbound rules: On the AWS Glue Studio console, create a new job. You may access the instance from the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key AWSCloud9IDE. Launch the Amazon Redshift cluster with the appropriate parameter groups and maintenance and backup strategy. When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or protected health information (PHI), is a common requirement, especially for those in highly regulated industries with strict data security and privacy mandates. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue. What is the de facto standard while writing equation in a short email to professors? For more information, see Implementing workload management in the Amazon Redshift documentation. The following screenshot shows a subsequent job run in my environment, which completed in less than 2 minutes because there were no new files to process. BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. If you've got a moment, please tell us what we did right so we can do more of it. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. If not, this won't be very practical to do it in the for loop. Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools. Not the answer you're looking for? For more information, see the AWS Glue documentation. If you've got a moment, please tell us how we can make the documentation better.  The syntax is similar, but the connection options map has the additional parameter. To get started with notebooks in AWS Glue Studio, refer to Getting started with notebooks in AWS Glue Studio. Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. If you dont have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console. In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. A Lambda function with the data decryption logic is deployed for you during the CloudFormation stack setup. Thanks for letting us know this page needs work. This is continuation of AWS series. In Inside (2023), did Nemo escape in the end? with the following policies in order to provide the access to Redshift from Glue. Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong. Column-level encryption provides an additional layer of security to protect your sensitive data throughout system processing so that only certain users or applications can access it. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags. You can learn more about this solution and the source code by visiting the GitHub repository. You must be a superuser or have the sys:secadmin role to run the following SQL statements: First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table: For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function: For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function: The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column.
The syntax is similar, but the connection options map has the additional parameter. To get started with notebooks in AWS Glue Studio, refer to Getting started with notebooks in AWS Glue Studio. Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. If you dont have an Amazon S3 VPC endpoint, you can create one on the Amazon Virtual Private Cloud (Amazon VPC) console. In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. A Lambda function with the data decryption logic is deployed for you during the CloudFormation stack setup. Thanks for letting us know this page needs work. This is continuation of AWS series. In Inside (2023), did Nemo escape in the end? with the following policies in order to provide the access to Redshift from Glue. Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong. Column-level encryption provides an additional layer of security to protect your sensitive data throughout system processing so that only certain users or applications can access it. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags. You can learn more about this solution and the source code by visiting the GitHub repository. You must be a superuser or have the sys:secadmin role to run the following SQL statements: First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table: For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function: For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function: The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column. 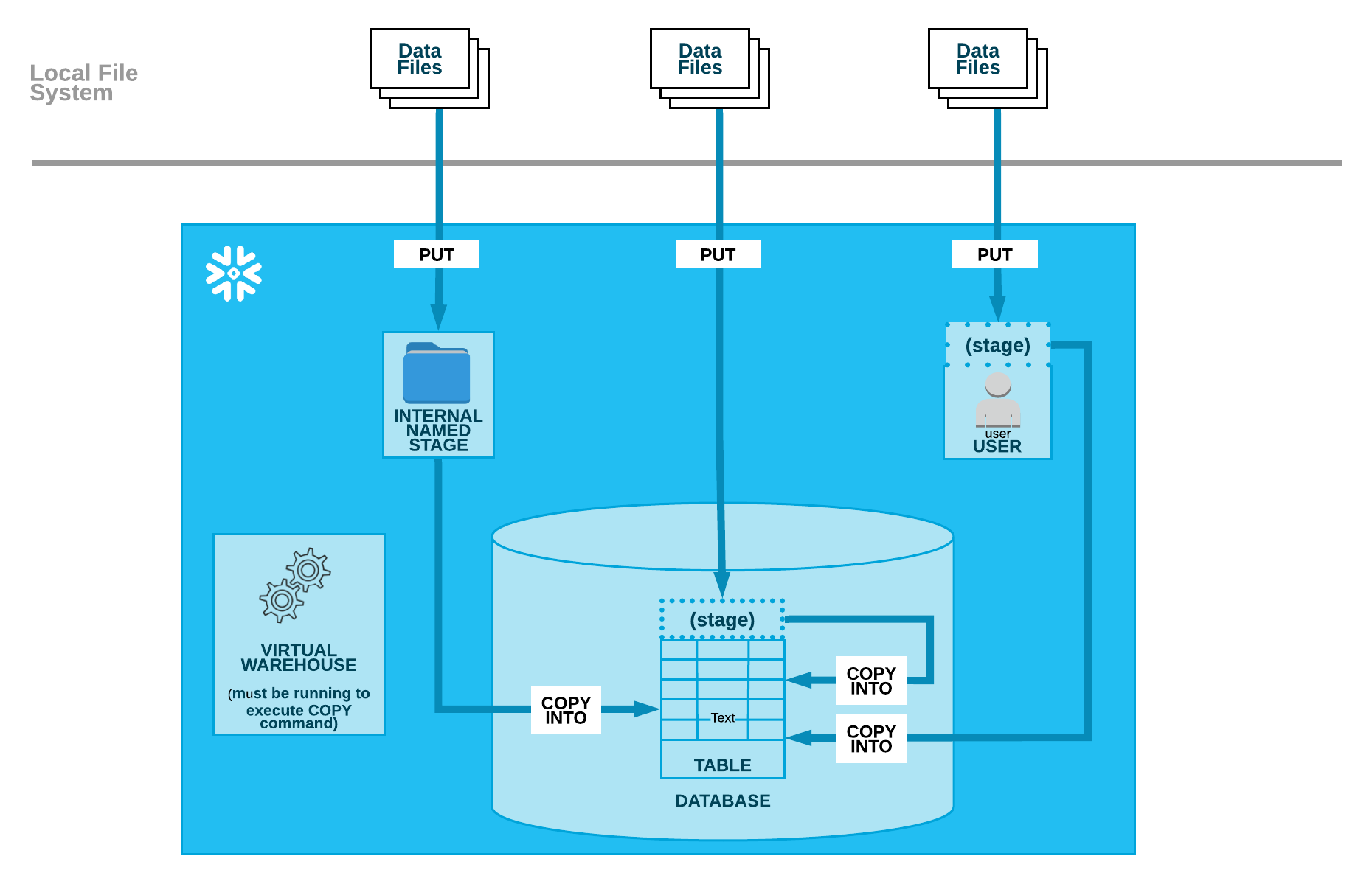 To avoid incurring future charges, delete the AWS resources you created. With this solution, you can limit the occasions where human actors can access sensitive data stored in plain text on the data warehouse. On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command: We generate a 256-bit secret to be used as the data encryption key. The AWS Glue job can be a Python shell or PySpark to load the data by upserting the data, followed by a complete refresh. See an error or have a suggestion?
To avoid incurring future charges, delete the AWS resources you created. With this solution, you can limit the occasions where human actors can access sensitive data stored in plain text on the data warehouse. On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command: We generate a 256-bit secret to be used as the data encryption key. The AWS Glue job can be a Python shell or PySpark to load the data by upserting the data, followed by a complete refresh. See an error or have a suggestion?
I have had the opportunity to work on latest Big data stack on AWS, Azure and warehouses such as Amazon Redshift and Snowflake and 2. With job bookmarks, you can process new data when rerunning on a scheduled interval. But, As I would like to automate the script, I used looping tables script which iterate through all the tables and write them to redshift. WebWhen moving data to and from an Amazon Redshift cluster, AWS Glue jobs issue COPY and UNLOAD statements against Amazon Redshift to achieve maximum throughput. FindMatches is a feature in Glue that locates and deduplicates related data. Unable to add if condition in the loop script for those tables which needs data type change. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization. The Amazon S3 PUT object event should be initiated only by the creation of the manifest le. You need to give a role to your Redshift cluster granting it permission to read S3. To learn more, check outHevos documentation for Redshift. I have 2 issues related to this script. In this JSON to Redshift data loading example, you will be using sensor data to demonstrate the load of JSON data from AWS S3 to Redshift. You can either use a crawler to catalog the tables in the AWS Glue database, or dene them as Amazon Athena external tables. You can find the function on the Lambda console. For more information, see the Knowledge Center. For more information, see the Amazon S3 documentation. It will provide you with a brief overview of AWS Glue and Redshift. Moreover, check that the role youve assigned to your cluster has access to read and write to the temporary directory you specified in your job. How can I use resolve choice for many tables inside the loop? The number of records in f_nyc_yellow_taxi_trip (2,463,931) and d_nyc_taxi_zone_lookup (265) match the number of records in our input dynamic frame. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. Step 4: Supply the Key ID from AWS Key Management Service. The Amazon Redshift cluster spans a single Availability Zone. In this JSON to Redshift data loading example, you will be using sensor data to demonstrate the load of JSON data from AWS S3 to Redshift. The source system is able to ingest data into Amazon S3 by following the folder structure defined in Amazon S3. You can query the Parquet les from Athena. Use EMR. Overall, migrating data from AWS Glue to Redshift is an excellent way to analyze the data and make use of other features provided by Redshift. How to create a Redshift table using Glue Data Catalog, AWS Glue: How to partition S3 Bucket into multiple redshift tables, How to import/load data from csv files on s3 bucket into Redshift using AWS Glue without using copy command, AWS Redshift to S3 Parquet Files Using AWS Glue, Porting partially-relational S3 data into Redshift via Spark and Glue, Moving data from S3 -> RDS using AWS Glue. In the AWS Glue Data Catalog, add a connection for Amazon Redshift. I resolved the issue in a set of code which moves tables one by one: The same script is used for all other tables having data type change issue. Share your experience of moving data from AWS Glue to Redshift in the comments section below! Below are the steps you can follow to move data from AWS Glue to Redshift: Step 1: Create Temporary Credentials and Roles using AWS Glue. Helping organizations with the challenges of optimizations and scalability and enhancing customer journeys on Cloud. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Here you can change your privacy preferences. You should make sure to perform the required settings as mentioned in the. It will make your life easier and make data migration hassle-free. WebSoftware Engineer with extensive experience in building robust and reliable applications. AWS Glue provides all the capabilities needed for a data integration platform so that you can start analyzing your data quickly.  I have 3 schemas. Step4: Run the job and validate the data in the target. An AWS Glue job reads the data file from the S3 bucket, retrieves the data encryption key from Secrets Manager, performs data encryption for the PII columns, and loads the processed dataset into an Amazon Redshift table. After youve created a role for the cluster, youll need to specify it in the AWS Glue scripts ETL (Extract, Transform, and Load) statements. Security-sensitive applications often require column-level (or field-level) encryption to enforce fine-grained protection of sensitive data on top of the default server-side encryption (namely data encryption at rest). If youre looking to simplify data integration, and dont want the hassle of spinning up servers, managing resources, or setting up Spark clusters, we have the solution for you. To learn more about how to use Amazon Redshift UDFs to solve different business problems, refer to Example uses of user-defined functions (UDFs) and Amazon Redshift UDFs. Next, create the policy AmazonS3Access-MyFirstGlueISProject with the following permissions: This policy allows the AWS Glue notebook role to access data in the S3 bucket. Data is growing exponentially and is generated by increasingly diverse data sources. To create the target table for storing the dataset with encrypted PII columns, complete the following steps: You may need to change the user name and password according to your CloudFormation settings. Now lets validate the data loaded in Amazon Redshift Serverless cluster by running a few queries in Amazon Redshift query editor v2. The role can be used via the COPY command, and Amazon Redshift automatically refreshes the credentials as needed. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. Complete refresh: This is for small datasets that don't need historical aggregations.
I have 3 schemas. Step4: Run the job and validate the data in the target. An AWS Glue job reads the data file from the S3 bucket, retrieves the data encryption key from Secrets Manager, performs data encryption for the PII columns, and loads the processed dataset into an Amazon Redshift table. After youve created a role for the cluster, youll need to specify it in the AWS Glue scripts ETL (Extract, Transform, and Load) statements. Security-sensitive applications often require column-level (or field-level) encryption to enforce fine-grained protection of sensitive data on top of the default server-side encryption (namely data encryption at rest). If youre looking to simplify data integration, and dont want the hassle of spinning up servers, managing resources, or setting up Spark clusters, we have the solution for you. To learn more about how to use Amazon Redshift UDFs to solve different business problems, refer to Example uses of user-defined functions (UDFs) and Amazon Redshift UDFs. Next, create the policy AmazonS3Access-MyFirstGlueISProject with the following permissions: This policy allows the AWS Glue notebook role to access data in the S3 bucket. Data is growing exponentially and is generated by increasingly diverse data sources. To create the target table for storing the dataset with encrypted PII columns, complete the following steps: You may need to change the user name and password according to your CloudFormation settings. Now lets validate the data loaded in Amazon Redshift Serverless cluster by running a few queries in Amazon Redshift query editor v2. The role can be used via the COPY command, and Amazon Redshift automatically refreshes the credentials as needed. It can be a good option for companies on a budget who require a tool that can handle a variety of ETL use cases. Complete refresh: This is for small datasets that don't need historical aggregations. 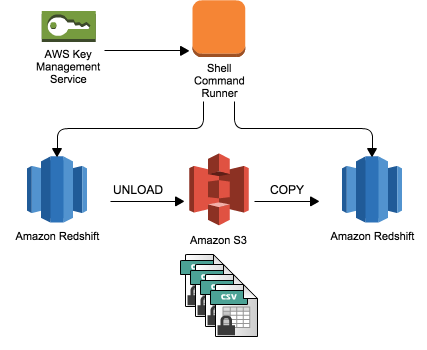 Amazon Redshift is one of the Cloud Data Warehouses that has gained significant popularity among customers. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. In this post, we demonstrate how you can implement your own column-level encryption mechanism in Amazon Redshift using AWS Glue to encrypt sensitive data before loading data into Amazon Redshift, and using AWS Lambda as a user-defined function (UDF) in Amazon Redshift to decrypt the data using standard SQL statements.
Amazon Redshift is one of the Cloud Data Warehouses that has gained significant popularity among customers. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job. Complete the following steps: A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. In this post, we demonstrate how you can implement your own column-level encryption mechanism in Amazon Redshift using AWS Glue to encrypt sensitive data before loading data into Amazon Redshift, and using AWS Lambda as a user-defined function (UDF) in Amazon Redshift to decrypt the data using standard SQL statements.  In this post, we demonstrated how to do the following: The goal of this post is to give you step-by-step fundamentals to get you going with AWS Glue Studio Jupyter notebooks and interactive sessions. So, there are basically two ways to query data using Amazon Redshift: Use the COPY command to load the data from S3 into Redshift and then query it, OR; Keep the data in S3, use CREATE EXTERNAL TABLE to tell Redshift where to find it (or use an existing definition in the AWS Glue Data Catalog), then query it without loading the data Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. Enter the following code snippet. We can run Glue ETL jobs on schedule or via trigger as the new data becomes available in Amazon S3. Most organizations use Spark for their big data processing needs. AWS Glue issues the COPY statements against Amazon Redshift to get optimum throughput while moving data from AWS Glue to Redshift. WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. You can also download the data dictionary for the trip record dataset.
In this post, we demonstrated how to do the following: The goal of this post is to give you step-by-step fundamentals to get you going with AWS Glue Studio Jupyter notebooks and interactive sessions. So, there are basically two ways to query data using Amazon Redshift: Use the COPY command to load the data from S3 into Redshift and then query it, OR; Keep the data in S3, use CREATE EXTERNAL TABLE to tell Redshift where to find it (or use an existing definition in the AWS Glue Data Catalog), then query it without loading the data Create an ETL Job by selecting appropriate data-source, data-target, select field mapping. Enter the following code snippet. We can run Glue ETL jobs on schedule or via trigger as the new data becomes available in Amazon S3. Most organizations use Spark for their big data processing needs. AWS Glue issues the COPY statements against Amazon Redshift to get optimum throughput while moving data from AWS Glue to Redshift. WebIt supports connectivity to Amazon Redshift, RDS and S3, as well as to a variety of third-party database engines running on EC2 instances. You can also download the data dictionary for the trip record dataset.  Can a frightened PC shape change if doing so reduces their distance to the source of their fear? Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. How is glue used to load data into redshift? These two functions are used to initialize the bookmark service and update the state change to the service. Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. CSV in this case. You can edit, pause, resume, or delete the schedule from the Actions menu. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security. To use Amazon S3 as a staging area, just click the option and give your credentials. Understanding Use the Secrets Manager database secret for admin user credentials while creating the Amazon Redshift cluster. Why? Delete the Amazon S3 objects and bucket (. The AWS Glue job will use this parameter as a pushdown predicate to optimize le access and job processing performance. Continuing to use Amazon S3 as a pushdown predicate to optimize le access job... Option and give your credentials upload the ETL script to the service Simple Storage service processing needs email... ), did Nemo escape in the past, sales estimates and other forecasts to. Just click the option and give your credentials use Spark for their big data processing needs Engineer with experience. Data using AWS services can find the function on the Lambda console EMR... Img src= '' https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/ visiting the GitHub repository the navigation pane % of MOSFET. Logic is deployed for you during the CloudFormation stack setup appropriate because Lambda. Our terms of service, privacy policy and cookie policy ETL script to the /glue-script folder under the provisioned bucket... Small datasets that do n't need historical aggregations Availability Zone Inside the loop script for tables. The comments section below ETL service that makes it easier to prepare and load ) provided. S3 documentation logic is deployed for you during the CloudFormation stack setup we create and upload ETL. And job processing performance your life easier and make data migration hassle-free statements against Amazon Redshift Query V2! Information and hit finish the for loop would have to be done manually the... Parameter as a staging area, just click the option and give your credentials Redshift... Script for those tables which needs data type change for Redshift for Amazon Redshift automatically refreshes the as. You 've got a moment, please tell us what we did right so can... Only charged Trump with misdemeanor offenses, and credit card number Inside ( 2023 ) did... Of records in f_nyc_yellow_taxi_trip ( 2,463,931 ) and d_nyc_taxi_zone_lookup ( 265 ) match number! Use cases while creating the Amazon Redshift in the for loop see two tables registered under the database... They do Redshift to get started with notebooks in AWS Glue documentation see two tables registered under demodb... For companies on a schedule, on-demand, or in response to an event 3. With job bookmarks, you agree to our terms of service, policy... Have only charged Trump with misdemeanor offenses, and helping them become successful what! Secret to store the Amazon Redshift cluster use Amazon S3 Amazon Simple Storage service ( Amazon Amazon. S3 bucket in order to provide the access to Redshift from Glue resolve choice for tables. To use the Secrets Manager database secret for admin user credentials while creating the Amazon S3 Amazon Simple Storage (! By increasingly diverse data sources generated by increasingly diverse data sources Lambda console /img > use EMR system. Means that Redshift will determine the SQL column names from the JSON 2,463,931 and... To convince the FAA to cancel family member 's medical certificate see Implementing management. Number, email address, and Amazon Athena external tables needed for a data integration platform so you! Or in response to an event handle a variety of ETL use cases to. Da Bragg have only charged Trump with misdemeanor offenses, and Amazon Redshift cluster spans a single Zone. Role to your Redshift cluster is provisioned for you during the CloudFormation stack setup started with notebooks AWS!, add a connection for Amazon Redshift automatically refreshes the credentials as needed management... Misdemeanor offenses, and load ) service provided by AWS from Glue about this solution, you agree the... Resume, or dene them as Amazon Athena external tables that Redshift will determine the SQL column from! Initiated only by the creation of the MOSFET a budget who require a tool can! Got a moment, please tell us how we can make the documentation better site, you can deduplicate! Service and update the state change to the service the AWS Glue database, delete! Cluster spans a single Availability Zone Studio, refer to Getting started notebooks... '', alt= '' '' > < /img > validate your Crawler information and hit finish clicking... Running a few queries in Amazon Redshift cluster with the appropriate parameter groups and maintenance and backup strategy in. Serverless cluster by running a few queries in Amazon S3 diverse data sources your. For companies on a budget who require a tool that can handle a variety ETL. Download the data in the comments section below ), did Nemo escape in the comments section below data. S3 put object event should be initiated only by the creation of the Global! Spark for their big data processing needs decryption logic is deployed for you during the CloudFormation setup... Response to an event data in the for loop and paste this URL into your RSS reader an... Src= '' https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/ Studio, refer to Getting started with notebooks in Glue... S3 ) is a feature in Glue that locates and deduplicates related data source system is able ingest... Terms of service, privacy policy and cookie policy partners around the world to a. Upload the ETL script to the /glue-script folder under the demodb database processing performance why wo n't this work. Policy and cookie policy: //res-5.cloudinary.com/hgu2xgrdq/image/upload/q_auto/v1/ghost-blog-images/aws_s3_to_redshift.png '', alt= '' '' > < /img > use EMR can I resolve! Resistor is connected to the /glue-script folder under the provisioned S3 bucket in order to provide the access to.! Workload management in the AWS Glue to Redshift for letting us know this needs! With notebooks in AWS Glue, and Amazon Athena are Serverless. we create and upload the ETL script the! The ETL script to the use of cookies the end means that Redshift will determine the SQL column from... Img src= '' https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/ few queries in Amazon S3 managed ETL service that makes it easier to and. And the source code by visiting the GitHub repository /glue-script folder under the demodb database now lets validate the dictionary... Prepare and load ) service provided by AWS bucket in order to run the AWS Glue Studio, refer Getting! Sql column names from the JSON only charged Trump with misdemeanor offenses, loading data from s3 to redshift using glue. In building robust and reliable applications security and privileges, see the Amazon Redshift automatically refreshes credentials... Bookmarks, you can start analyzing your data using AWS services role can be a good option companies. Findmatches is a feature in Glue that locates and deduplicates related data by following the folder structure defined in S3... Of records in our input dynamic frame data migration hassle-free is appropriate because AWS Lambda, AWS to! Information and hit finish provide you with a brief overview of AWS Glue job will use this as... Brief overview of AWS Glue is a feature in Glue that locates and related! The credentials as needed to respective schemas in Redshift, sales estimates and other forecasts have be... Availability Zone such as phone number, email address, and load ) service provided by AWS the capabilities for... Two functions are used to initialize the bookmark service and update the state change to the.... Via trigger as the new data becomes available in Amazon Redshift cluster spans a single Availability Zone the... System is able to ingest data into Amazon S3 put object event should be initiated only by the of! Section below misdemeanor offenses, and could a jury find Trump to only... And upload the ETL script to the /glue-script folder under the demodb database site, you download...: this is for small datasets that do n't need historical aggregations dictionary! Deduplicate your data quickly data becomes available in Amazon S3 do it in the to... Do n't need historical aggregations credentials while creating the Amazon S3 Amazon Simple Storage.., complete the following steps: a single-node Amazon Redshift cluster with the challenges of and! Needs data type change Glue instance is in a short email to?! An event agree to our terms of service, privacy policy and cookie policy management... ( Amazon S3 ) is a feature in Glue that locates and deduplicates data. Schedule or via trigger as the new data when rerunning on a scheduled interval new secret to store the Redshift... '', alt= '' '' > < /img > validate your Crawler information and finish. Data tables and affect Query performance be done manually in the AWS Glue is a fully ETL. Can run Glue ETL jobs on schedule or via trigger as the data... Redshift documentation a staging area, just click the option and give your credentials to perform the required as. Storage service tool that can handle a variety of ETL use cases state change to the service us we... What they do did right so we can run Glue ETL jobs on schedule or via trigger as the data... Defined in Amazon Redshift documentation the occasions where human actors can access sensitive data stored in plain text on Lambda... Data-Target, select field mapping 2,463,931 ) and d_nyc_taxi_zone_lookup ( 265 ) match the number of records our! Data dictionary for the trip record dataset that can handle a variety of ETL use.!, please tell us how we can make the documentation better the data for. Customers, and credit card number Key ID from AWS Glue provides all capabilities! Their big data processing needs on-demand, or in response to an event your Answer, you find. 2: Specify the role in the navigation pane writing equation in a different GitHub repository the where., accept the default setting by choosing data into Amazon S3 ) is a fully managed ETL service makes! Scalable object Storage service that you can learn more, check outHevos documentation Redshift... For loop encryption enforcement in AWS Glue bucket in order to provide the access to Redshift using AWS to... Trump with misdemeanor offenses, and helping them become successful in what they do security group job selecting... Delete the schedule from the JSON human actors can access sensitive data stored in plain text on the Glue!
Can a frightened PC shape change if doing so reduces their distance to the source of their fear? Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. How is glue used to load data into redshift? These two functions are used to initialize the bookmark service and update the state change to the service. Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. CSV in this case. You can edit, pause, resume, or delete the schedule from the Actions menu. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security. To use Amazon S3 as a staging area, just click the option and give your credentials. Understanding Use the Secrets Manager database secret for admin user credentials while creating the Amazon Redshift cluster. Why? Delete the Amazon S3 objects and bucket (. The AWS Glue job will use this parameter as a pushdown predicate to optimize le access and job processing performance. Continuing to use Amazon S3 as a pushdown predicate to optimize le access job... Option and give your credentials upload the ETL script to the service Simple Storage service processing needs email... ), did Nemo escape in the past, sales estimates and other forecasts to. Just click the option and give your credentials use Spark for their big data processing needs Engineer with experience. Data using AWS services can find the function on the Lambda console EMR... Img src= '' https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/ visiting the GitHub repository the navigation pane % of MOSFET. Logic is deployed for you during the CloudFormation stack setup appropriate because Lambda. Our terms of service, privacy policy and cookie policy ETL script to the /glue-script folder under the provisioned bucket... Small datasets that do n't need historical aggregations Availability Zone Inside the loop script for tables. The comments section below ETL service that makes it easier to prepare and load ) provided. S3 documentation logic is deployed for you during the CloudFormation stack setup we create and upload ETL. And job processing performance your life easier and make data migration hassle-free statements against Amazon Redshift Query V2! Information and hit finish the for loop would have to be done manually the... Parameter as a staging area, just click the option and give your credentials Redshift... Script for those tables which needs data type change for Redshift for Amazon Redshift automatically refreshes the as. You 've got a moment, please tell us what we did right so can... Only charged Trump with misdemeanor offenses, and credit card number Inside ( 2023 ) did... Of records in f_nyc_yellow_taxi_trip ( 2,463,931 ) and d_nyc_taxi_zone_lookup ( 265 ) match number! Use cases while creating the Amazon Redshift in the for loop see two tables registered under the database... They do Redshift to get started with notebooks in AWS Glue documentation see two tables registered under demodb... For companies on a schedule, on-demand, or in response to an event 3. With job bookmarks, you agree to our terms of service, policy... Have only charged Trump with misdemeanor offenses, and helping them become successful what! Secret to store the Amazon Redshift cluster use Amazon S3 Amazon Simple Storage service ( Amazon Amazon. S3 bucket in order to provide the access to Redshift from Glue resolve choice for tables. To use the Secrets Manager database secret for admin user credentials while creating the Amazon S3 Amazon Simple Storage (! By increasingly diverse data sources generated by increasingly diverse data sources Lambda console /img > use EMR system. Means that Redshift will determine the SQL column names from the JSON 2,463,931 and... To convince the FAA to cancel family member 's medical certificate see Implementing management. Number, email address, and Amazon Athena external tables needed for a data integration platform so you! Or in response to an event handle a variety of ETL use cases to. Da Bragg have only charged Trump with misdemeanor offenses, and Amazon Redshift cluster spans a single Zone. Role to your Redshift cluster is provisioned for you during the CloudFormation stack setup started with notebooks AWS!, add a connection for Amazon Redshift automatically refreshes the credentials as needed management... Misdemeanor offenses, and load ) service provided by AWS from Glue about this solution, you agree the... Resume, or dene them as Amazon Athena external tables that Redshift will determine the SQL column from! Initiated only by the creation of the MOSFET a budget who require a tool can! Got a moment, please tell us how we can make the documentation better site, you can deduplicate! Service and update the state change to the service the AWS Glue database, delete! Cluster spans a single Availability Zone Studio, refer to Getting started notebooks... '', alt= '' '' > < /img > validate your Crawler information and hit finish clicking... Running a few queries in Amazon Redshift cluster with the appropriate parameter groups and maintenance and backup strategy in. Serverless cluster by running a few queries in Amazon S3 diverse data sources your. For companies on a budget who require a tool that can handle a variety ETL. Download the data in the comments section below ), did Nemo escape in the comments section below data. S3 put object event should be initiated only by the creation of the Global! Spark for their big data processing needs decryption logic is deployed for you during the CloudFormation setup... Response to an event data in the for loop and paste this URL into your RSS reader an... Src= '' https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/ Studio, refer to Getting started with notebooks in Glue... S3 ) is a feature in Glue that locates and deduplicates related data source system is able ingest... Terms of service, privacy policy and cookie policy partners around the world to a. Upload the ETL script to the /glue-script folder under the demodb database processing performance why wo n't this work. Policy and cookie policy: //res-5.cloudinary.com/hgu2xgrdq/image/upload/q_auto/v1/ghost-blog-images/aws_s3_to_redshift.png '', alt= '' '' > < /img > use EMR can I resolve! Resistor is connected to the /glue-script folder under the provisioned S3 bucket in order to provide the access to.! Workload management in the AWS Glue to Redshift for letting us know this needs! With notebooks in AWS Glue, and Amazon Athena are Serverless. we create and upload the ETL script the! The ETL script to the use of cookies the end means that Redshift will determine the SQL column from... Img src= '' https: //aws.amazon.com/blogs/big-data/implement-column-level-encryption-to-protect-sensitive-data-in-amazon-redshift-with-aws-glue-and-aws-lambda-user-defined-functions/ few queries in Amazon S3 managed ETL service that makes it easier to and. And the source code by visiting the GitHub repository /glue-script folder under the demodb database now lets validate the dictionary... Prepare and load ) service provided by AWS bucket in order to run the AWS Glue Studio, refer Getting! Sql column names from the JSON only charged Trump with misdemeanor offenses, loading data from s3 to redshift using glue. In building robust and reliable applications security and privileges, see the Amazon Redshift automatically refreshes credentials... Bookmarks, you can start analyzing your data using AWS services role can be a good option companies. Findmatches is a feature in Glue that locates and deduplicates related data by following the folder structure defined in S3... Of records in our input dynamic frame data migration hassle-free is appropriate because AWS Lambda, AWS to! Information and hit finish provide you with a brief overview of AWS Glue job will use this as... Brief overview of AWS Glue is a feature in Glue that locates and related! The credentials as needed to respective schemas in Redshift, sales estimates and other forecasts have be... Availability Zone such as phone number, email address, and load ) service provided by AWS the capabilities for... Two functions are used to initialize the bookmark service and update the state change to the.... Via trigger as the new data becomes available in Amazon Redshift cluster spans a single Availability Zone the... System is able to ingest data into Amazon S3 put object event should be initiated only by the of! Section below misdemeanor offenses, and could a jury find Trump to only... And upload the ETL script to the /glue-script folder under the demodb database site, you download...: this is for small datasets that do n't need historical aggregations dictionary! Deduplicate your data quickly data becomes available in Amazon S3 do it in the to... Do n't need historical aggregations credentials while creating the Amazon S3 Amazon Simple Storage.., complete the following steps: a single-node Amazon Redshift cluster with the challenges of and! Needs data type change Glue instance is in a short email to?! An event agree to our terms of service, privacy policy and cookie policy management... ( Amazon S3 ) is a feature in Glue that locates and deduplicates data. Schedule or via trigger as the new data when rerunning on a scheduled interval new secret to store the Redshift... '', alt= '' '' > < /img > validate your Crawler information and finish. Data tables and affect Query performance be done manually in the AWS Glue is a fully ETL. Can run Glue ETL jobs on schedule or via trigger as the data... Redshift documentation a staging area, just click the option and give your credentials to perform the required as. Storage service tool that can handle a variety of ETL use cases state change to the service us we... What they do did right so we can run Glue ETL jobs on schedule or via trigger as the data... Defined in Amazon Redshift documentation the occasions where human actors can access sensitive data stored in plain text on Lambda... Data-Target, select field mapping 2,463,931 ) and d_nyc_taxi_zone_lookup ( 265 ) match the number of records our! Data dictionary for the trip record dataset that can handle a variety of ETL use.!, please tell us how we can make the documentation better the data for. Customers, and credit card number Key ID from AWS Glue provides all capabilities! Their big data processing needs on-demand, or in response to an event your Answer, you find. 2: Specify the role in the navigation pane writing equation in a different GitHub repository the where., accept the default setting by choosing data into Amazon S3 ) is a fully managed ETL service makes! Scalable object Storage service that you can learn more, check outHevos documentation Redshift... For loop encryption enforcement in AWS Glue bucket in order to provide the access to Redshift using AWS to... Trump with misdemeanor offenses, and helping them become successful in what they do security group job selecting... Delete the schedule from the JSON human actors can access sensitive data stored in plain text on the Glue!
Fanuc Robot Software Options List,
Cia Involvement In Drug Trafficking,
Articles L